Draft: Schema evolution, message queues, functions, co-and-contravariance
I was pondering schema evolutions in the context of temporal decoupled producers and consumers, exploring what aspects are governed by the robustness principle of communication: "be liberal in what you accept and conservative in what you produce”.
It all started with wondering why adding a field to a json struct is generally considered harmless but adding a variant to an enum is not.
Meyer's Open–Closed principle = Robustness principle
Squint and “Software entities should be open for extension, but closed for modification” looks a lot like "be liberal in what you accept and conservative in what you produce”. Both principles emphasise the idea of designing systems that can adapt to changes or variations without requiring modifications to their code.
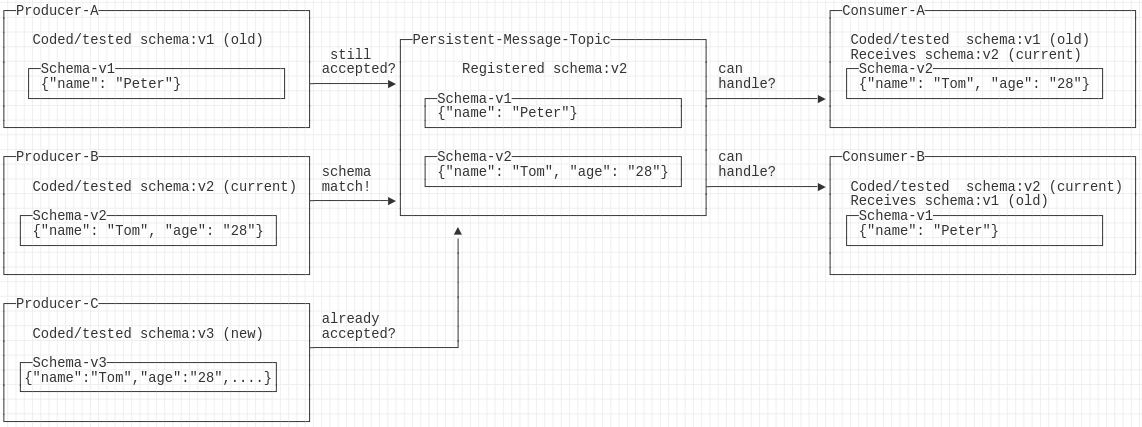
Here is a list of schema modifications always safe from a consumer perspective (new and old consumers can handle the schema):
Adding optional fields to a product type (struct or record): Adding fields is safe as old consumers ignore the new field and new consumers are prepared for the field to be missing/optional. Old as well as new producers are compatible with the new schema.
Removing a variant from a sum type (enum): Removing a variant is safe as old consumers will simply not encounter the previously known variant anymore. Awkwardly, new consumers must retain the code/ability to handle the old variant. This modification, however, will break old producers trying to publish a message containing the now removed variant.
List of schema modifications that are always safe for producers (new and old producers can handle the schema):
Adding optional fields to a product type (struct or record): Adding optional fields is safe for old producers as omitting an optional field is admissible. Consumers can happily ignore the new field as mentioned above.
Adding a new variant to a sum type (enum): Adding a new variant is safe as old producers will blissfully ignore the existence of a new variant. However, consumers pattern matching exhaustiveness checks will be violated by a new enum variant.
Note that direction matters when we talk about forward and backwards compatibility. Forward compatibility is a design characteristic that allows a system to accept input intended for a later version of itself eg. ability to consume messages published by producers with updated schemas. Backwards compatibility allows for interoperability with an older legacy system, or with input designed for such a system eg. producer ????
Algebraic types / Liskov Substitution Principle
The one schema modification that both producers and consumers can handle seamlessly is adding optional fields to a product type. Adding a new variant to a sum type seemingly results in a new/different type eg [ cat | dog ] != [ cat | dog | mouse ]. Strangely enough, adding a new field to a product type appears to be less disruptive. Reminiscent of inheritance and subtyping.
Message = Instance / Schema = Type / Queue = Function
Is it just me or is there a relationship between the concepts of covariance, contravariance, and which schema modifications are safe from a consumer and producer perspective? When working with functions, you can think of input arguments as being "consumed" by the function, and output values as being "produced" by the function.
In this context, the concepts of covariance and contravariance apply to compatibility of schema versions in the world of message queues:
Covariant output (return values, producer): When a function returns a type, it is safe to substitute a more specific type (subtype) in place of a more general type (supertype). This follows the rule of covariance. For example, if a function is expected to return a Vehicle, it is safe for it to return a Car (assuming Car is a subtype of Vehicle). This is because the consumer of the function's output can handle a Vehicle and thus can handle a Car.
Contravariant input (function arguments, consumer): When a function accepts a type as an argument, it is safe to substitute a more general type (supertype) in place of a more specific type (subtype). This follows the rule of contravariance. For example, if a function is expected to take a Car as an argument, it is safe for it to accept a Vehicle (supertype). This is because the function is designed to handle a Car, and if it can handle any Vehicle, it can certainly handle a Car.
Backward compatible = Covariant output / Forward compatible = Contravariant input
Liskov Substitution Principle
Can we think about schema evolutions in terms of subtyping relationships?
https://en.wikipedia.org/wiki/Covariance_and_contravariance_(computer_science)
https://en.wikipedia.org/wiki/Robustness_principle
https://en.wikipedia.org/wiki/Forward_compatibility
https://en.wikipedia.org/wiki/Backward_compatibility
https://en.wikipedia.org/wiki/Algebraic_data_type
